性能优化的维度
- 程序设计优化
- Java 代码调优
- JVM 调优
- 数据库调优
- 数据库调优
基准测试
- JMH Java 性能测试
- 数据性能测试
常用指标和计算公式
QPS 计算公式
QPS = (1 / t ) * n
一秒内可以处理的请求数量称之为服务器的QPS。
上面我们计算了10000个请求的耗时,那么反过来计算每秒处理多少请求则
如果一次性可以处理100个请求,每个请求耗时100毫秒,则qps = 1000
如果一次性可以处理50个请求,每个请求耗时200毫秒,则qps = 250
程序设计优化
缓冲技术
缓冲技术用于协调不同系统之间的性能差异。例如文件流写入磁盘的速度慢,程序就会阻塞,缓冲像一个漏斗,先存放到内存,应用程序可以完成操作,缓冲慢慢释放内容到文件。缓冲可以大幅度提高 IO 效率。
BufferedWriter
用于包装 writer,构造函数的第二个参数可以指定缓冲区大小,默认为 8K。
BufferedWriter bw = new BufferedWriter(new FileWriter(new File("test.txt"))) ;
bw.write("hello");
bw.write("world");
bw.flush();
bw.close();
BufferedOutputStream
用于包装输出流,构造函数的第二个参数可以指定缓冲区大小,默认为 8K。
FileOutputStream fos=new FileOutputStream("test.txt");
BufferedOutputStream bos=new BufferedOutputStream(fos);
String content="hello world!";
bos.write(content.getBytes(),0,content.getBytes().length);
bos.flush();
bos.close();
缓存技术
不一定是所有从数据库读出的数据才需要缓存,很多数据都可以被缓存,例如网络请求、复杂计算,这些数据可以被零时缓存到内存中。
EhCache 进程内缓存
mybatis、shiro、hibernate 中的一级缓存都是 EhCache。默认内存缓存,可以配置为磁盘、外部介质。
远程 API 操作
// 1. 创建缓存管理器
CacheManager cacheManager = CacheManager.create("./src/main/resources/ehcache.xml");
// 2. 获取缓存对象
Cache cache = cacheManager.getCache("HelloWorldCache");
// 3. 创建元素
Element element = new Element("key1", "value1");
// 4. 将元素添加到缓存
cache.put(element);
// 5. 获取缓存
Element value = cache.get("key1");
System.out.println(value);
System.out.println(value.getObjectValue());
// 6. 删除元素
cache.remove("key1");
使用Spring 注解操作
@Cacheable
修饰的方法执行后就将返回值放入缓存,不再执行。表明所修饰的方法是可以缓存的,这个注解可以用condition属性来设置条件
@Cacheable(value="UserCache", key="'user:' + #userId")
public User findById(String userId) {
return (User) new User("1", "mengdee");
}
@CacheEvict
和 Cacheable 相反,执行后根据规则清空缓存。
@CacheEvict(value="UserCache",key="'user:' + #userId")
public void removeUser(User user) {
System.out.println("UserCache"+user.getUserId());
}
池化技术
对象池
java中的对象池技术,是为了方便快捷地创建某些对象而出现的,当需要一个对象时,就可以从池中取一个出来(如果池中没有则创建一个),则在需要重复重复创建相等变量时节省了很多时间。
Java 中数据类型的包装类型支持基本的对象池技术。
线程池
多线程可以充分利用多核 CPU 的使用率。使用线程池可以大幅度提高多线程性能,下面是一个线程池的例子,推荐使用 Executors 创建线程:
ExecutorService executor = Executors.newFixedThreadPool(10);
executor.execute(new MyThread());
executor.shutdown;
线程池的数量非常重要,《Java 并发编程实践》中给出了一个公式
Ncpu = CPU 的数量
Ucpu = 目标 CPU 的使用率
W/C = 等待时间与计算时间的比率
Nthreads = 合理的线程数量
Nthreads = Ncpu * Ucpu * (1 + W/C)
连接池
数据库连接池使用 C3P0、DBCP、HikariCP和Druid,spring 推荐使用 DBCP,但是 Druid 支持监控,可以对慢 SQL 进行分析。
Java 代码调优
字符串优化
优先使用字面量,而不是 new String();
String str = "";
// 优于
String str1 = new String();
优先使用 StringTokenizer 分隔字符串
只用 charAt 进行字符串比较
优先使用 StringBuilder 和 StringBuffer
合理选用数据结构
列表
ArrayList 通过数组实现,每次扩容会造成大量的性能消耗,适合读多写少的操作,注意设置初始数组大小。
LinkedList 通过双向链表实现,查询效率低,写入速度快,适合写多读少。
Vector ArrayList 的线程安全实现,性能相差无几, 适合写多读少的场景。
CopyOnWriteArray 通过 COW 技术实现线程安全的实现,适合读多写少操作。
Map
HashMap 注意设置负载因子降低冲突
LinkedHaspMap 在读取时排序,内部基于链表,适合写多读少
TreeMap 实现了 sortedMap 满足对有序性的需求,在写入时排序,内部基于红黑树,适合读多写少
ConcurrentHashMap 是线程安全且高性能的额 Map 容器,使用了 CAS、红黑树、分段锁等技术。
Set
满足 Map 的无重复性需求
HashSet,对应 HashMap,基于hash的快速插入
LinkedHashSet,对应 LinkedHashMap,基于 hash 的插入,维护了插入集合的先后顺序个。按照先进先出的顺序排序
TreeSet,对应 Tree Map 基于红黑树的实现。有高效的元素 key 的排序算法
RandomAccess 随机访问接口
用于标记是是否支持随机访问,提高代码性能:
if(list isntanceof RandomAccess){
// 随机访问
}else{
// 老老实实使用迭代器
}
使用 NIO
TODO
合理使用引用类型
强引用
Java默认的引用方式,存在引用的情况下可以不会被回收。
软引用
通过 SoftReference 使用软引用,当 内存达到一定阈值,GC会回收。
弱引用
GC 运行时会被回收,但是 GC 不会随时运行,因此可以利用这个特性实现某些缓存机制。
某些数据(缓存)放到一个超大的 map中会造成内存泄露,因此可以使用 WeakHashMap 来自动释放。
虚引用
深入理解JAVA虚拟机一书中有这样一句描述:“为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知”。
虚引用更多的是用于对象回收的监听。
- 重要对象回收监听 进行日志统计
- 系统gc监听 因为虚引用每次GC都会被回收,那么我们就可以通过虚引用来判断gc的频率,如果频率过大,内存使用可能存在问题,才导致了系统gc频繁调用
其他技巧
少使用异常
使用局部变量
局部变量在栈中,类变量在堆中。
使用位运算
使用移位运算代替乘法除法(计算机实现原理)
替换 switch
一维数组代替二维数组
使用 arrayCopy
使用 Buffer 对 IO进行包装
使用 clone() 代替new
clone 会绕过构造函数
静态方法代替实例方法
并发调优
并发基础
volatile
线程会对变量局部更新,提高性能。volatile 变量可见性保证,这是并发编程的基础
- 其他线程对变量的修改,理解反应到当前线程中
- 确保当前线程对 volatile 的修改,能即时写回共享主内存中,并被其他线程所见
- 使用 volatile 声明的变量,编译器会保证有序性
同步关键字 synchronized
Java 中最基本的锁机制,可以锁方法、变量、类、静态方法等资源, synchronized 为公平锁。
线程局部变量 ThreadLocal
线程执行时独立的内存空间,在某些业务场景下可以用来实现并发操作,避免锁的使用。
信号量 Semaphore
锁是对单个资源的控制,型号量可以对一组资源管理,例如 100 个线程的线程池,可以定义一个型号量 100,当型号量小于 100 时,请求才允许被加入。
锁优化
锁的分类
- 乐观锁/悲观锁
- 乐观锁:就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。典型的是使用版本号更新前判断。
update xxx when version =xxx;如果版本号不匹配更新失败。在Java中 CAS 就是乐观锁。 - 悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁。synchronized 就是悲观锁,mysql 中就是 readForUpdate 语句。
- 乐观锁:就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。典型的是使用版本号更新前判断。
- 独享锁/共享锁
- 独享锁是指该锁一次只能被一个线程所持有,例如 Synchronize、ReentrantLock。
- 共享锁是指该锁可被多个线程所持有。
- 互斥锁/读写锁
- 互斥锁在Java中的具体实现就是ReentrantLock。
- 读写锁在Java中的具体实现就是ReadWriteLock、ReentrantReadWriteLock
- 可重入锁
- 上锁后每个访问的线程都需要排队,可重入的意思是已经获取锁的线程再次进入无需排队,避免死锁。可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。
- 公平锁/非公平锁
- 公平锁是指多个线程按照申请锁的顺序来获取锁。ReetrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。
- 非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,按照CPU运行时间片来划分的。ReetrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。Synchronized 也是一种非公平锁,无法变成公平锁。
- 分段锁
- 分段锁其实是一种锁的设计,并不是具体的一种锁。ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7和JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表。当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在哪一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。统计 Size 的时候需要全局加锁才能统计
- 偏向锁/轻量级锁/重量级锁
- 这三种锁是指锁的状态,并且是针对Synchronized。
- 偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。
- 轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞。
- 重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。
- 自旋锁
- 在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
AQS 技术
AbstractQueuedSynchronized 抽象队列式的同步器,AQS定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的ReentrantLock/Semaphore/CountDownLatch
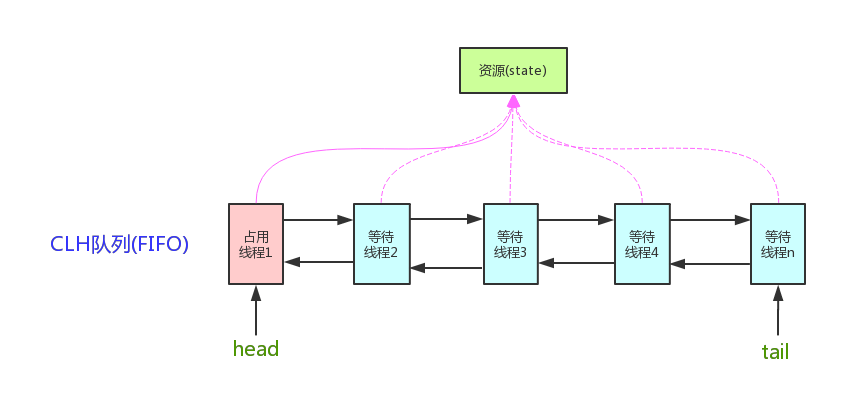
想要获取锁的线程通过 CAS 设置资源计数器,当资源计数器为0时,队列开始移动,否则进行排队操作。
避免死锁
死锁会造成线程挂起彼此等待,死锁可以 dump 出栈空间即可分析。
死锁产生的必要条件:
- 互斥条件:一个资源每次只能被一个进程使用
- 请求与保持条件:一个进程因请求资源被阻塞,对已经获得的资源保持不放
- 不剥夺条件:进程获得的资源,在未使用完之前,不能强行剥夺
- 循环等待等待条件:若干进程之间形成了一个等待资源的循环
常见的死锁就是分布式锁和数据库锁之间的的矛盾。
例如 数据库某行记录 A,某个变量 B,两个线程分别获得了锁,然后互相等待对方释放。
减少锁持有时间和颗粒度
当锁不可避免时,应该减少锁的持有时间和颗粒度。
- synchronized 只锁变量不要锁类,注意 self 和 this的区别
- 数据库锁行,而不要锁表
- 使用分段锁减少锁的颗粒度
使用读写分离锁来替换独占锁
读一般无需上锁,因此不应该将所有的请求都上锁,只对写上锁即可。
锁分离思想
根据读写分离锁的思想,更新、删除或其他操作都可以分别上锁,而不是一个大锁。
例如 LinkedblockingQueue 基于链表,那么 take 和 put 操作可以分开上锁,减少锁竞争。
合理使用重入锁和内部锁 (synchronized)
优先使用内部锁,减少编程复杂度,需要时再使用 ReentrantLock
锁粗化 (Lock Coarsening)
锁粗化是相对于锁细粒度的另外一个极端情况的,当锁粒度过于细,反复获取锁也是不对的,应该保持适度。
在循环体中不应该使用锁,而是应该在循环体外使用锁,否则锁会反复被获取和释放。
开启 JVM 锁自璇
如果一个锁反复没有获取,线程切换的成本很高,还不如让它执行空循环(自旋)。
=XX:+UseSpinning
开启自旋
开启 JVM 自动锁消除
有一些程序不必要使用锁,例如局部变量,JVM 可以优化为开启自旋锁。
-server -XX:+DoEsccapeAnalysis -XX:+EliminateLocks
开启逃逸分析和锁消除。
开启锁偏向
如果没有发生竞争就进入锁偏向模式,关闭同步操作,用于优化不激烈的锁场景,这个优化场景意义不大。
-XX:+UseBiasedLocking
无锁并行计算设计
无锁的算法实际上就是一些乐观锁 CAS、COW等。
原子操作
在 atomic 包下有一些原子操作类,大量使用 CAS 技术,非常有用。
例如 AtomicInteger.addAndGet() 通过一个无穷循环 CAS 直到成功。
Amino 框架
提供了一些成熟的无锁数据结构。
JVM 调优
JVM 输出调试信息
-XX:+PrintGCDetails
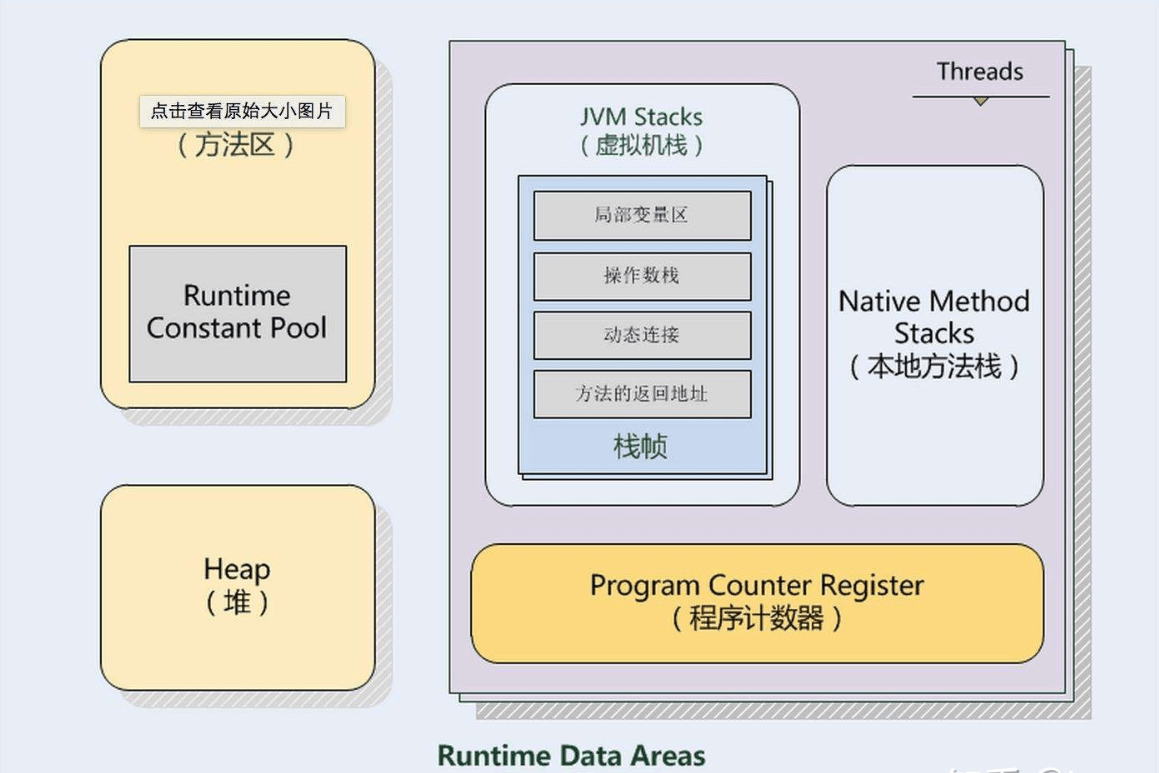
虚拟机内存模型
JVM 虚拟机模型
堆内存模型
程序计数器
虚拟机栈
栈的大小决定了函数调用可达的深度,-Xss 设置栈的大小,一般无需设置此参数,应该消除递归代码
一般设置为 -Xss1M
另外,函数嵌套调用次数由栈的大小决定。栈越大,函数的嵌套调用次数越多。对一个函数而言,它的参数越多,内部局部变量越多,栈帧就越大,嵌套调用次数就会减少。
本地方栈
本地方法栈为 java 原生函数调用使用的空间。
Java 堆
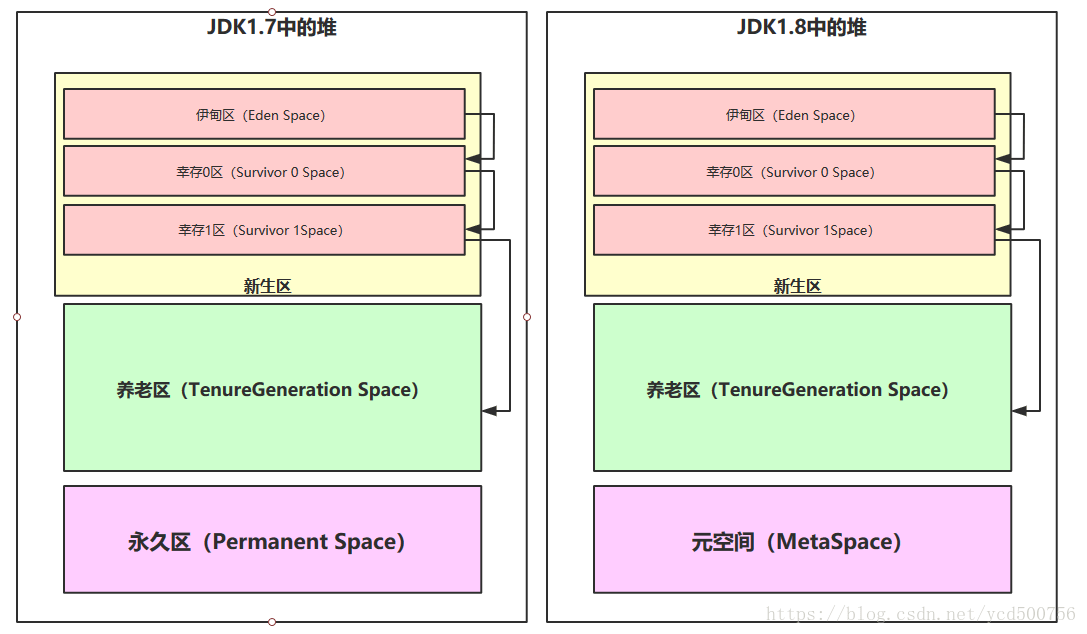
Java 堆为Java对象存储位置。采用分代内存回收策略:
- 新生代
- eden 伊利园
- s0 survior
- s1 survior
- 老年代
使用 -XX 参数设置
方法区
方法去也可称为永久区,主要存放常量和类的定义信息。
JVM 内存分配参数
设置最大堆内存
-Xmx
默认为物理内存的四分之一,一般可以开启到物理内存一致。
设置最小堆内存
-Xms
JVM启动会先按照最小堆内存运行,然后尝试运行时申请更多内存。如果最小堆内存过小,就会频繁触发 GC。
包括 Minor GC和Full GC。
JVM 会试图将内存尽可能限制在 -Xms 中。因此,当内存实际使用量初级 -Xms 指定的大小时,会触发 Full GC。因此 -Xms 值设置为 -Xmx 可以减少GC的次数和耗时。
这个操作的前提是,需要预知系统内存使用量。
设置新生代
-Xmn
设置一个较大的新生代会减少老年代的大小,这个参数对系统性能以及 GC 行为有很大的影响。新生代的大小一般设置为整个堆空间的 1/4 左右。
设置持久代
-XX:MaxPerSize
持久代(方法区)不属于堆的一部分,持久代决定了系统可以支持多少个类定义和多少常量。如果使用了 CGlib 或者 Javassist 等动态字节码技术的程序,需要合理设置。
一般来说,设置为 64M 已经够用,如果出现溢出,可以设置为 128M。
如果 128M依然不能满足,不应该继续增加参数值。而是优化程序设计。
设置线程栈
-Xss
线程栈是线程的一块私有空间,决定了支持线程的数量。
如果线程栈的空间很大,则允许支持的线程数量就会减少,因此这个值需要合理设置。
由于堆的增加会挤占栈空间的大小,因此设置这个参数需要和堆大小合理取舍。
堆的比例分配
新生代和S区域的比例
-XX:SurviorRation=eden/s0=eden/s1
堆参数设置总结
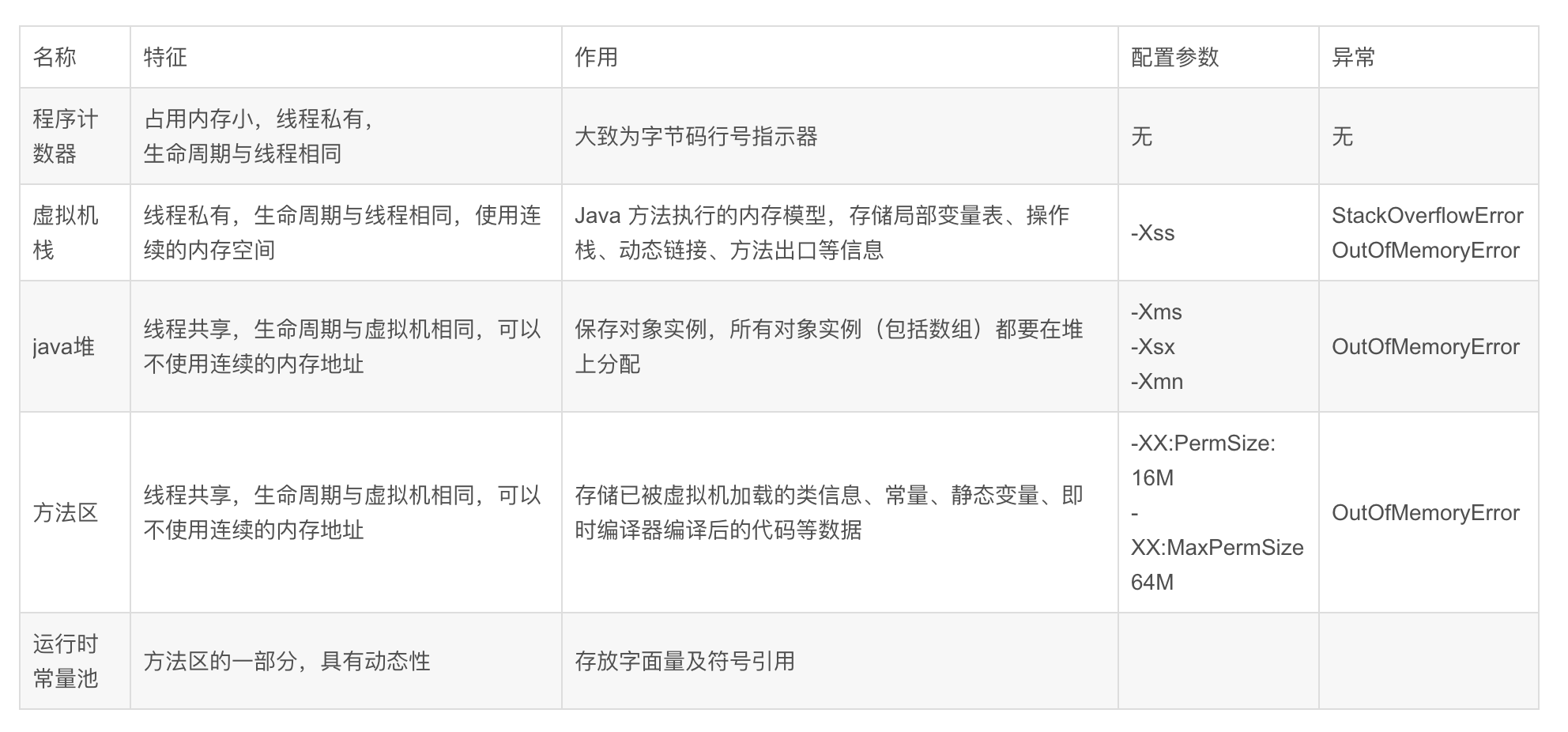
- -Xms:初始堆大小
- -Xmx:最大堆大小
- -Xss:线程栈的大小
- -XX:NewSize:设置新生代大小
- -XX:PermSize:永久区的初始值
- -XX:MaxPermSize:永久区的最大值
- -XX:MinHeapFreeRatio:设置堆空间最小空闲比例
- -XX:MaxHeapFreeRatio:设置堆空间最大空闲比例
- -XX:NewRatio:设置老年代与新生代的比例
- -XX:SurviorRatio:新生代中eden区域survivior区的比例
垃圾收集基础
jdk 垃圾回收器设置策略
- OpenJDK 8 使用 Parallel GC
- OpenJDK 8 提供了Parallel GC、CMS 和 G1 三种收集算法
比较
- Parallel GC JDK 默认设置,关注吞吐量,服务器调优优先推荐使用这个值
- G1 关注暂停
- CMS 关注 gc 时间
调优方法
调优需要搞清楚自己想要什么,这是最重要的,通过基准测试,明白现状,结合硬件平台和业务类型调优。
调优往往有几个目的:
- 提高吞吐量
- 减少停顿
- 出现内存泄漏、死锁等问题需要查找
调优建立在一个合理的背景下,JDK 默认的设置能满足大部分场景需要,是比较均衡的,一般来说无需调优。兼顾内存分配的灵活性(多个java应用同时存在)、吞吐量、停顿时间。只有需要侧重调整的时候才需要调优。例如为了高吞吐量,内存分配灵活性就没意义了,让单个java应用初始堆大小直接设置为预期值,可以减少 gc 次数。另外为了高吞吐量,在服务器开发中停顿可以在一定程度上容忍,可以选择对提高吞吐量友好的 gc 回收器。
一般来说,提高吞吐量、减少停顿是比较矛盾的两个指标。
另外,应用性能下降和内存泄漏、死锁等问题有关,解决问题后,性能就会极大的提升。
提高吞吐量配置方案
在服务器开发中,吞吐量比系统短时间停顿更重要,优先选用 Parallel GC ,合理设置堆大小。以 8G4U 的服务器来说,如果只部署单应用,可以参考以下参数:
java -Xmx7800m -Xms7800 -Xmn4g -Xss128k -XX:+UseParallelGC -XX:ParallelGC-Threads=4 -XX:+UseParallelOldGC
- -Xmx7800m -Xms7800 设置最大堆等于初始值,让内存全部给 java 应用使用,让最大堆等于初始值可以避免 运行初期堆内存不足造成的频繁GC。
- -Xmn4g 这是新生代大小,这个需要结合程序设计,以及内存分析结果设置
- -Xss128k 尽量减小线程栈,可以支持更多的线程
- -XX:+UserParallelGC 新生代使用 UserParallelGC
- -XX:+UserParallelOldGC 老年代使用 UserParallelGC
减低停顿时间的案例
对于老年代使用 CMS G减低停顿。尽可能让对象留在新生代,然后被 Minor GC回收,因此设置 eden 和 survivor 区的比例为 8:1,让对象尽可能留在新生代,如果 survivor 不够用,会直接进入老年代。
java -Xmx7800m -Xms7800 -Xmn4g -Xss128k -XX:ParallelGC-Threads=4 -XX:+ConcMarkSweepGC -XX:+UseParNewGC -XX:SurvivorRatio=8:1 -XX:TargetSurvivor-Ratio=90 -XX:MaxTenuringThreshold=30
- -Xmx7800m -Xms7800 -Xmn4g -Xss128k 设置堆和线程栈
- -XX:+UseParNewGC 为新生代使用 ParallelGC
- -XX:+ConcMarkSweepGC 整体使用 CMS
- -XX:SurvivorRatio=8:1 Survivor 比例为 80%
- -XX:TargetSurvivor-Ratio=90 Survivor可用比例,默认是 50%,如果超过这个值就会向老年代压缩。
- -XX:ParallelGC-Threads=4 GC 回收线程
- -XX:MaxTenuringThreshold=30 设置年轻对象进入老年代的阈值,默认是 15,就是15次 Minor GC依然存活就会进入老年代,这里设置为30,降低进入老年代的概率。
实用的 JVM 参数
查看 GC 分配情况
java -XX:+PrintGCDetails -version
[root@localhost ~]# java -XX:+PrintGCDetails -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
Heap
PSYoungGen total 17408K, used 922K [0x00000000ece00000, 0x00000000ee100000, 0x0000000100000000)
eden space 15360K, 6% used [0x00000000ece00000,0x00000000ecee6810,0x00000000edd00000)
from space 2048K, 0% used [0x00000000edf00000,0x00000000edf00000,0x00000000ee100000)
to space 2048K, 0% used [0x00000000edd00000,0x00000000edd00000,0x00000000edf00000)
ParOldGen total 39936K, used 0K [0x00000000c6a00000, 0x00000000c9100000, 0x00000000ece00000)
object space 39936K, 0% used [0x00000000c6a00000,0x00000000c6a00000,0x00000000c9100000)
Metaspace used 2418K, capacity 4480K, committed 4480K, reserved 1056768K
class space used 233K, capacity 384K, committed 384K, reserved 1048576K
查看 GC 参数
[root@localhost ~]# java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=60045120 -XX:MaxHeapSize=960721920 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
开启 JIT 编译参数
-XX:CompileThreadhold
设置阈值,Java 代码进入 JIT 编译模型。
堆 dump
-XX: + HeapDumpOnOutOfMemoryError
内存溢出时,dump 堆内存信息,还可以设置导出的位置
-XX: HeapDumpPath
发生 OOM 时候执行一段脚本
-XX: OnOutOfMemoryError=./restart.sh
可以在发生内存溢出时候重启服务, 或者通知
常用的 JVM 工具
jps
列出 java 的进程,类似于 ps 命令,不过只对 java 进程起作用,通过 jps 命令可以方便的查看 java 的进程启动类、传入参数和 JVM 参数等信息。
[root@localhost software]# jps
29328 Jps
1734 jenkins.war
711 spring-boot-boilerplate.jar
1502 UnixLauncher
参数 -m 可以输出传递给 Main 函数的参数:
1734 jenkins.war --logfile=/var/log/jenkins/jenkins.log --webroot=/var/cache/jenkins/war --daemon --httpPort=8000 --debug=5 --handlerCountMax=100 --handlerCountMaxIdle=20 --prefix=
711 spring-boot-boilerplate.jar --spring.profiles.active=dev
29369 Jps -m
1502 UnixLauncher start 9d17dc87 org.sonatype.nexus.karaf.NexusMain
参数 -l 可以输出主函数的完整路径:
[root@localhost software]# jps -v
1734 jenkins.war -Dcom.sun.akuma.Daemon=daemonized -Djava.awt.headless=true -Djenkins.install.runSetupWizard=false -DJENKINS_HOME=/var/lib/jenkins
711 spring-boot-boilerplate.jar
29389 Jps -Dapplication.home=/opt/oracle/jdk1.8.0_131 -Xms8m
1502 UnixLauncher -Dinstall4j.jvmDir=/opt/oracle/jdk1.8.0_131 -Dexe4j.moduleName=/usr/local/nexus/bin/nexus -XX:+UnlockDiagnosticVMOptions -Dinstall4j.launcherId=245 -Dinstall4j.swt=false -Di4jv=0 -Di4jv=0 -Di4jv=0 -Di4jv=0 -Di4jv=0 -Xms1200M -Xmx1200M -XX:MaxDirectMemorySize=2G -XX:+UnlockDiagnosticVMOptions -XX:+UnsyncloadClass -XX:+LogVMOutput -XX:LogFile=/usr/local/nexus/sonatype-work/nexus3/log/jvm.log -XX:-OmitStackTraceInFastThrow -Djava.net.preferIPv4Stack=true -Dkaraf.home=. -Dkaraf.base=. -Dkaraf.etc=etc/karaf -Djava.util.logging.config.file=etc/karaf/java.util.logging.properties -Dkaraf.data=/usr/local/nexus/sonatype-work/nexus3 -Djava.io.tmpdir=/usr/local/nexus/sonatype-work/nexus3/tmp -Dkaraf.startLocalConsole=false -Di4j.vpt=true
参数 -v 可以显示传递给 JVM 的参数:
[root@localhost software]# jps -v
29411 Jps -Dapplication.home=/opt/oracle/jdk1.8.0_131 -Xms8m
1734 jenkins.war -Dcom.sun.akuma.Daemon=daemonized -Djava.awt.headless=true -Djenkins.install.runSetupWizard=false -DJENKINS_HOME=/var/lib/jenkins
711 spring-boot-boilerplate.jar
jstat 命令
jstat 可以查看某个 java 进程运行时的工具,非常强大,可以非常详细的查看 Java 应用程序的堆使用情况,以及 GC 情况。
例如,每秒钟统计一次类装载信息,共统计两次:
[root@localhost software]# jstat -class -t 711 1000 2
Timestamp Loaded Bytes Unloaded Bytes Time
998981.4 14249 25586.8 0 0.0 127.05
998982.5 14249 25586.8 0 0.0 127.05
查看 JIT 编译信息:
[root@localhost software]# jstat -compiler -t 711
Timestamp Compiled Failed Invalid Time FailedType FailedMethod
999312.5 8453 2 0 115.88 1 org/springframework/core/annotation/AnnotatedElementUtils searchWithGetSemanticsInAnnotations
查看 GC 信息:
[root@localhost software]# jstat -gc 711
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
14848.0 9728.0 0.0 9427.4 99840.0 26216.5 73728.0 54161.6 76544.0 72788.4 10240.0 9518.9 49 2.662 3 2.449 5.111
查看 GC 和各个代的当前大小:
[root@localhost software]# jstat -gccapacity 711
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
19456.0 313344.0 129536.0 14848.0 9728.0 99840.0 39936.0 626688.0 73728.0 73728.0 0.0 1116160.0 76544.0 0.0 1048576.0 10240.0 49 3
查看新生代 gc 信息:
[root@localhost software]# jstat -gcnew 711
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
14848.0 9728.0 0.0 9427.4 15 15 14848.0 99840.0 26466.1 49 2.662
查看老年代 gc 信息:
[root@localhost software]# jstat -gcold 711
MC MU CCSC CCSU OC OU YGC FGC FGCT GCT
76544.0 72788.4 10240.0 9518.9 73728.0 54161.6 49 3 2.449 5.111
查看老年代容量信息:
[root@localhost software]# jstat -gcoldcapacity 711
OGCMN OGCMX OGC OC YGC FGC FGCT GCT
39936.0 626688.0 73728.0 73728.0 49 3 2.449 5.111
查看 gc 信息:
[root@localhost software]# jstat -gcutil 711
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 96.91 27.43 73.46 95.09 92.96 49 2.662 3 2.449 5.111
jinfo
jinfo 可以查看应用的拓展参数,甚至修改。
查看是否开启 GC 信息打印:
[root@localhost software]# jinfo -flag PrintGCDetails 711
-XX:-PrintGCDetails
说明没有开启 GC 信息的打印,通过 jinfo 临时开启:
[root@localhost software]# jinfo -flag +PrintGCDetails 711
[root@localhost software]# jinfo -flag PrintGCDetails 711
-XX:+PrintGCDetails
jmap
用于 dump 出堆的快照和统计信息
[root@localhost software]# jmap -histo 711 > /tmp/711.txt
[root@localhost software]# cat /tmp/711.txt
num #instances #bytes class name
----------------------------------------------
1: 139944 15081784 [C
2: 21776 14906296 [B
3: 10836 11056152 [I
4: 722 11023664 [J
5: 172795 5529440 java.util.HashMap$Node
6: 128993 3095832 java.lang.String
7: 33636 2959968 java.lang.reflect.Method
8: 70700 2262400 com.mysql.cj.conf.BooleanProperty
9: 15974 1987576 [Ljava.util.HashMap$Node;
10: 56835 1818720 java.util.concurrent.ConcurrentHashMap$Node
11: 15264 1685896 java.lang.Class
更有用的是导出堆信息:
[root@localhost software]# jmap -dump:format=b,file=./711.hprof 711
Dumping heap to /opt/software/711.hprof ...
Heap dump file created
[root@localhost software]# ls
711.hprof
快照信息可以通过 Visual VM 和 jhat 命令分析。
jhat
jhat 可以分析 jmap 导出的文件,然后启动一个 HTTP 服务器展示分析结果。
[root@localhost software]# jhat 711.hprof
Reading from 711.hprof...
Dump file created Fri Mar 20 22:17:18 CST 2020
Snapshot read, resolving...
Resolving 1337950 objects...
Chasing references, expect 267 dots...........................................................................................................................................................................................................................................................................
Eliminating duplicate references...........................................................................................................................................................................................................................................................................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
jstack
可以打印出栈信息,包括线程、锁的信息,如果发现死锁信息,可以自动识别:
[root@localhost software]# jstack -l 711
2020-03-20 22:21:40
Full thread dump OpenJDK 64-Bit Server VM (25.131-b12 mixed mode):
"Attach Listener" #10160 daemon prio=9 os_prio=0 tid=0x00007f65840a8800 nid=0x74dc waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
Locked ownable synchronizers:
- None
"lettuce-eventExecutorLoop-1-3" #49 daemon prio=5 os_prio=0 tid=0x00007f65b92e7800 nid=0x934 waiting on condition [0x00007f65607e8000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000c7b3d718> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at io.netty.util.concurrent.SingleThreadEventExecutor.takeTask(SingleThreadEventExecutor.java:238)
at io.netty.util.concurrent.DefaultEventExecutor.run(DefaultEventExecutor.java:64)
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:905)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- None
jstatd
jstatd 可以启动一个远程调试端口,允许 jps、jstat 等工具远程访问,因为权限的原因,直接使用 jstatd 会报错。需要配置 policy 文件。
使用 vim 创建一个文件如下:
vim jstatd.all.policy
grant codebase "file:/opt/oracle/jdk1.8.0_131/lib/tools.jar"{
permission java.security.AllPermission;
};
[root@localhost ~]# jstatd -J-Djava.security.policy=./jstatd.all.policy
默认开启端口 1099
[root@localhost ~]# jps localhost:1099
31136 Jps
1734 jenkins.war
711 spring-boot-boilerplate.jar
1502 UnixLauncher
这样可以让调试非常方便,同时可视化的分析工具也可以通过个 jstatd 提供的服务连接到需要分析的服务器。
hprof 工具
除了使用 jstatd 让目标服务器提供一个远程服务用于调试之外,还可以让 java 应用通过 agent 的方式启动,得到该应用的调试信息。
Java -agentlib:hprof=heap=dump,format=b,file=/tmp/app.hprof -jar xxx.jar
除了 hprof 之外,市面上还有一些远程监控 java 应用的 apm 工具和平台,例如听云 apm。
spring actuator
spring boot 的项目可以引入 spring-actuator,监控应用。actuator 功能之一就是导出堆信息 。
如果使用 maven 作为构建工具,引入包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
spring-actuator 会提供很多用于度量项目的接口,其中可使用 heapdump 端口导出堆信息
wget http://localhost:1001/monitor/actuator/heapdump
然后通过 VisualVM 或者 MAT 分析
MAT 内存分析工具
TODO
VisualVM 分析工具
TODO
操作系统调优
linux 常用调优命令
Top
top -hv | -bcHiOSs -d secs -n max -u|U user -p pid(s) -o field -w [cols
使用 top 可以观察各个进程对 CPU 的占用和内存使用情况。
sar
sar 可以对内存和 CPU 的使用情况进行采样
统计 CPU 情况,每秒钟采样一次,共计采样 3 次
Sar -u 1 3
获取内存使用情况
sar -r 1 3
获取 I/O 信息
L sar -b 1 3
vmstart
vm start 是一个功能更为齐全的工具,需要单独安装,也可以安装 busybox
vmstat 1 3
Iostat
iostat 1 2
可以查看CPU和磁盘IO信息
pidstat
可以查询某个线程的状态,找出那个线程造成了大量的IO、CPU使用率,然后通过 jps、jstack 分析该线程的 IO情况。
对线程 1520 cpu 使用率 每秒钟采样 1 次,总计采样 3次。
pidstat -p 1520 -u 1 3
对线程 1520 io 使用率 每秒钟采样 1 次,总计采样 3次。
pidstat -p 1520 -d -t 1 3